Digital imaging workflow
I posted two articles on workflow for digital images and how to use IMatch‘s sophisticated category management system to best effect for asset management.
I posted two articles on workflow for digital images and how to use IMatch‘s sophisticated category management system to best effect for asset management.
When you first start tinkering with digital imaging, you do things by the seat of the pants, and after a while you realize you need a more disciplined approach to have a manageable setup. The result is called a workflow.
Each person’s workflow is slightly different, but the following rough steps are common to everyone:
What hardware you use for acquisition controls the final quality of your results, so:
Using a slide/negative scanner is a very slow and laborious process, and a preferable option in many cases is to have scans made by a photo lab. Avoid the low quality Kodak PictureCD and opt instead for PhotoCD Master, which has higher resolution and scans made more carefully.
Getting rid of the chaff early is a major step in improving your productivity, but it is difficult to be objective about one’s own photos. This process is sometimes also known as editing, although this term lends itself to confusion with digital imaging. Here is a good introductory article on the subject: Give That Cat The Boot: Editing 101.
For most of the other phases, the choice of software does not matter very much and will indeed change over time. It is essential to get asset management right up-front, however. The solution you use must be
The best program I’ve found so far is IMatch (Windows only, I’m afraid), mostly because of its incredibly flexible category system, that works like set theory with multiple inclusion relationships and boolean operators. I have posted a more detailed overview of how to use IMatch for image category management. As I have switched to the Mac, my current asset management program is Kavasoft Shoebox, which has the same power as IMatch and a much better user interface to boot, but is not scriptable.
The most comprehensive description of a Photoshop editing workflow is available here on Michael Reichmann’s Luminous Landscape site.
As I’ve mentioned elsewhere, my preferred output method used to be prints made on a Fuji Frontier digital minilab system. Unfortunately, most labs are clueless about color management and cropping, and I now use an Epson R1800 archival pigment ink printer. People who want to print digital black & white prints may opt for the R2400 instead.
This is essential if you do not want all your hard work above to go in smoke in case of a hard drive failure.
Media failures are not the only kind of disaster that can destroy your digital images, fire, theft, flooding and earthquakes are also a consideration, depending on where you live. Most companies have a disaster recovery plan (at least on paper), most individuals should have a simplified one for their personal effects as well. I am not just talking about photos: scanning property titles, diplomas and other vital documents is an inexpensive precaution.
Sticking to a diet is hard. So is sticking to a backup plan, for human factors and process-related reasons, not technical ones. If your chosen backup method is so cumbersome you don’t apply it regularly, it is not going to do you much good. You should focus on developing a process that fits your risk sensitivity as well as your time and budget, and if your current approach is not sustainable, reexamine your backup requirements to fit within what you can do on a regular basis. A weekly or monthly backup schedule should not be too onerous for most people.
The backup process should also involve periodic verification of the backups, so that media failure can be detected and corrected immediately. This implies redundancy in the backup, as well as diversification (use media of different types, or different manufacturers, to avoid simultaneous failure from systemic causes). If you wait 5 years until you actually need the backup, Murphy’s law will inevitably strike.
CD-R and DVD-R media are the cheapest per megabyte, but I am not convinced of their archival characteristics (some published tests have shown CD-Rs can become unreadable in as little as 2 years). 70 or 80GB DLT tape cartridges (and other tape technologies like DAT DDS, 8mm, VXA or LTO) offer high capacity and are durable, but tape drives are very expensive, unreliable and usually available only in SCSI.
Just as the watched pot does not boil over, online data like that stored on external hard drives is harder to misplace than removable media. The solution I use is to make two backups onto two external 250GB firewire hard drives (under about $1 a gigabyte as of July 2005). I rotate them weekly between home and my office, so even if my apartment burns down, I will have lost at most a week’s worth of pictures.
If you prefer CD-R or DVD-R, be sure to use reliable brands like Mitsui Gold and follow the NIST guidelines for their care and handling (here is the PDF one-page summary).
For the backup software, I do not trust proprietary indexing formats and use a regular filesystem with incremental disk to disk copies using XXCOPY on Windows, LaCie’s free SilverKeeper utility on Mac OS X, and Rsync on UNIX.
Format obsolescence is a factor, although the magnitude of the risk is often overblown. While JPEG and TIFF are likely to be supported well into the future, manufacturers’ proprietary RAW image formats (for digital cameras) are less likely to. When a format becomes obsolete, it should be converted to a more durable one, obviously before the OS and drivers for it have become nonfunctional.
Finally, we are all mortal. If you were to disappear tomorrow, would your loved ones know how to retrieve your photos? Making prints of the best ones is a low-tech but robust way of ensuring their passage over time, possibly even skipping generations.
I have discussed digital imaging workflows elsewhere. In this article, I would like to focus on the asset management using IMatch.
The main reason why I selected IMatch is for its advanced category management. This masquerades as a hierarchical system, but it is actually a full-blown set theoretical system with:
Inclusion relationships: if a category is under a more general category, anytime you search for the more general category, the images under the more specific category will also appear, without having to assign them to the more general category explicitly as well.
Multiple inclusion (a category can belong to multiple larger categories.
Derived categories: you can have categories that are defined using boolean formulas of categories and file system folder location.
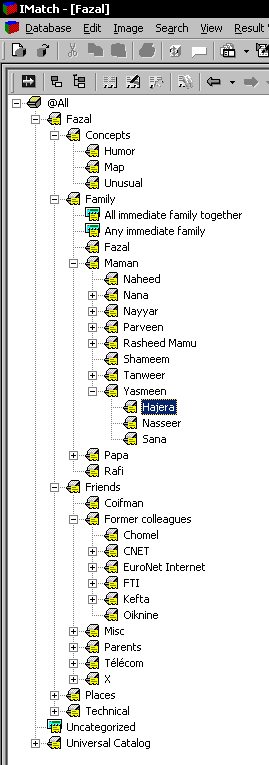
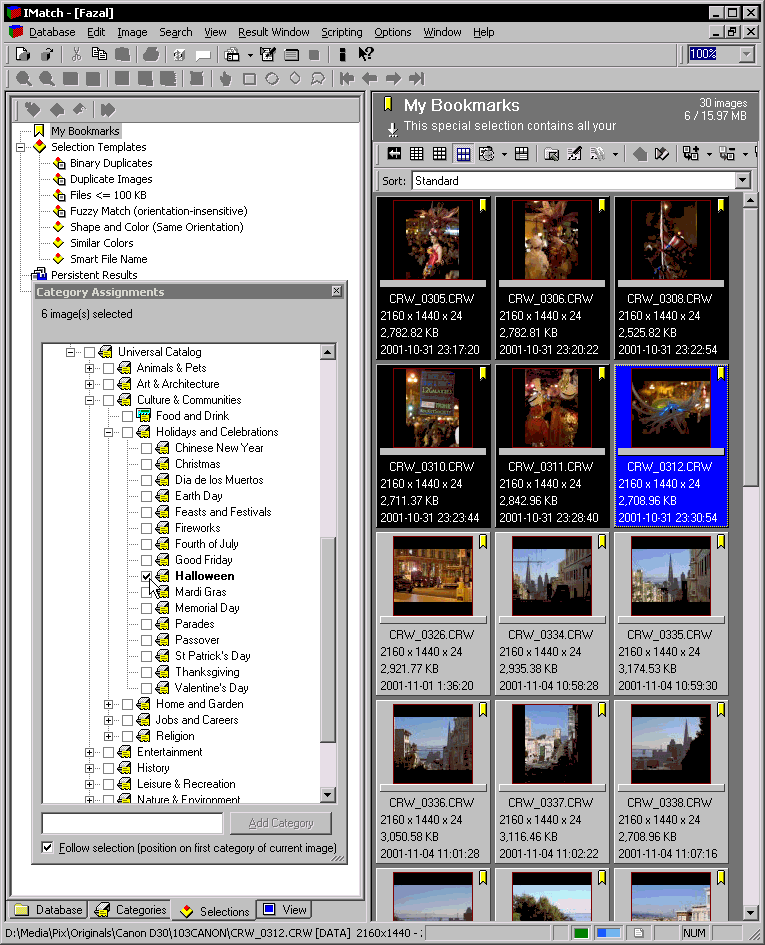
To the left is a screenshot of the category window in IMatch.
It is very important to give some prior thought to how one’s categories will be organized, just as for librarians the choice of a catalog system like the Dewey decimal index is almost a matter of religion. A poorly designed category schema will almost inevitably entail at some point in time having to laboriously reassign categories.
The figure to the left shows my categories. I try and have a hierarchy where the most specific category (leaf categories in the tree) have a manageable number of images. If there are too many (more than a couple hundred), this means I have to break down the category into smaller, more specific subcategories.
Obviously, pictures of friends and family make a substantial proportion of my image catalog, so it is important to have a manageable approach to those.
For family, I use an inverted family tree: a family tree centered on myself, and then expanding on my father’s and mother’s side of the family, and so on, so that the path I take to get to the category for a relative. In the example on the left, I can get to the category for my cousin Hajera as follows:
My family
My mother’s side
My mother’s sister Yasmeen
Her daughter Hajera
This scheme is very simple and extensible, and avoids bunching all relatives together in a single disorganized mess.
In practice, however, I make some small adjustments that break this general approach. For instance, I have a separate category for my mother herself (“Naheed”, just under “Maman” – yes, I think in a mix of French and English), because otherwise whenever I would select the category for my mother, all her side of the family would appear as well, and the same thing for my grandmother. Andy Katayama describes a more systematic way to deal with these situations.
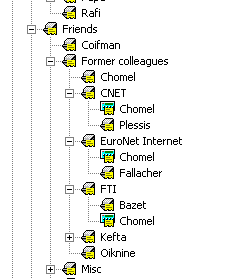
For friends, I use an approach where I organize them by how I met them (school, work, and so on). Sometimes, a single friend can belong to multiple categories, which is where IMatch’s multiple inclusion scheme comes in handy.
For instance, Bruno Chomel is an ex-colleague from three different companies, so I have link category to him in each of the three companies’ categories, as shown in the figure to the right.
I also have some special-purpose categories. “Concepts” is used for categories that encompass abstract concepts like humorous pictures. “Technical” is used for things like flagging pictures that are part of a panoramic set, or my best pictures.
Finally, I have a category “Places” that is used to indicate the geographic location for photos that have a distinguishing landmark in them, and this category is organized hierarchically by continent, then country, state, city and so on.
In addition to these categories I defined myself, I also use the standard “Universal” category schema supplied with IMatch for standard categories like “People & Relationships / Weddings” or “Culture & Communities / Holidays & Celebrations / Thanksgiving”.
As an example of a derived category, here is the property box for the “Uncategorized” category I use for all images that do not have any category assigned.
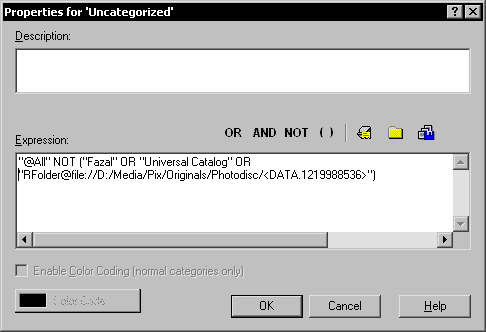
This formula means “all pictures that are not categorized under Fazal’s user-defined category schema or the Universal category schema supplied with IMatch, and that are not part of the Photodisc folder”. The expression for the Photodisc folder looks intimidating, but I actually entered it using the second button above, which allows me to enter a specific folder from a pop-up menu.
For an asset management system to be viable, it shouldn’t take too much time. Systems that require you to enter captions are too burdensome for regular use, but categories strike the right balance, as long as they can be assigned to large numbers of images efficiently.
IMatch offers a number of time-saving features like splashers (a small drop-down menu that allows you to assign your most-frequently used categories to an image in two clicks), but in many cases this is not enough.
I import photos from my digital camera in batches of between 50 and 300, and I use the following algorithm to make assignments quickly. I have used this technique to categorize over a thousand images in less than an hour.
First, when importing the images (by clicking on the rescan button in the filesystem view of the database after importing the images), check the option to bookmark new images. Then go to the bookmarked images selection to view all of them.
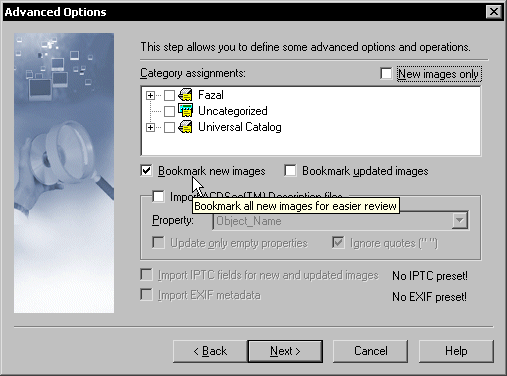
Look at the first image, and pick a category among those that fit it. Control-click on all images that are also in that category, and then assign the category to all of them in one go using the category assignment dialog. Repeat if there are more categories to assign to the first image. Once all categories for the first image are exhausted, toggle the bookmark on it to make it disappear from the view. Usually, the next few images also have no categories remaining so you can take out a batch. You then repeat with the next image that has categories remaining to be assigned, and repeat the process until all categories have been assigned.
For fans of Ansel Adams, the Library of Congress has an online exhibit based on his book “Born Free and Equal”. This book is a series of photographs taken at the Manzanar camp in California where Japanese-Americans were interned during World War II.
A book version has been reprinted.
Update (2002-09-16): This article in The Atlantic sheds some light on the background for the original exhibition.
The optimal line length for readability is around 10-12 words (Source by Ruari McLean)
The ratio of peak load to average load in a service with diurnal activity variations is approximately 3 to 1. Source: my own empirical observation from Wanadoo access logs and France Telecom telephone call usage logs.
Probability of a Web page having X incoming links referring to it: P = X ^ -2.1 (Source)
When specifying computers, for balanced performance provision one gigabyte of RAM per gigahertz per core/thread.
Any standard making use of ASN.1 is a piece of junk.
You only get the benefits of statistical multiplexing or compression once, and it should only be done in one layer. Any other layers attempting to do the same only add cost, complexity, brittleness, overhead and latency.
When designing high-availability systems, fail-over is not the hard part, falling back is.
For most ordinary lenses, optimal sharpness is around f/8. For high-quality lenses, it is one or two stops below full aperture. Only the very best lenses are diffraction-limited and offer optimal performance at full aperture.
Camera light meters are calibrated for 12% gray. Common gray cards are 18% gray, so if you use one for metering, you should open up one half stop to compensate. (Source)
The human eye is a 6-7 megapixel sensor. The monocular field of view is 180 °, the binocular field of view is 120-140°, and the normal focus of attention spans a 45° field of view.
Avoid Kodak products like the plague. Those products they make that are actually decent (i.e. the engineers managed to sneak them past the bean counters) soon get adulterated (like Tri-X) or discontinued (like PhotoCD or their medium-format digital backs). Prefer Fuji, Agfa or Ilford.